* MongoDB 기능
NoSQL 데이터베이스이기 때문에 MongoDB에는 많은 훌륭한 기능이 있습니다. 작업에 도움이 될 몇 가지 MongoDB 기능에 대해 알아보겠습니다.
- Ad-jpc 쿼리
- 스키마 없는 데이터베이스
- 문서 지향
- 인덱싱
- 복제
- 집합체
- GridFS
- 샤딩
- 고성능

1. Ad-hoc 쿼리
일반적으로 데이터베이스의 스키마를 설계할 때 수행할 쿼리에 대해 미리 알 수 없습니다. Ad-hoc 쿼리는 데이터베이스를 구조화하는 동안 알려지지 않은 쿼리입니다. MongoDB는이 경우 매우 특별하게 만드는 Ad-hoc 쿼리 지원을 제공합니다. Ad-hoc 쿼리는 실시간으로 업데이트되어 성능이 향상됩니다.
Ad-hoc 쿼리는 예약되지 않은 데이터 쿼리로, 미리 결정되거나 미리 정의된 데이터 세트로 해결할 수 없는 질문이 발생할 때 생성되는 경우가 많습니다.
Ad-hoc 쿼리는 분석 인프라에서 지원하는 가장 중요하고 가치 있는 분석 유형 중 하나입니다. 가장 중요한 분석 질문 중 다수는 일반적인 비즈니스 작업과 일상적인 분석의 결과로 떠오릅니다. 많은 조직이 비즈니스 인텔리전스 도구 및 데이터 웨어하우스를 통해 언제든지 임시 쿼리를 지원합니다.

2. 스키마 없는 데이터베이스
MongoDB에서 하나의 컬렉션은 다른 문서를 보유합니다. 스키마가 없으므로 동일한 컬렉션의 다른 문서와 다른 많은 필드, 콘텐츠 및 크기를 가질 수 있습니다. 이것이 MongoDB가 데이터베이스를 다루는 데 유연성을 보이는 이유입니다.
스키마가 없는 데이터베이스는 데이터가 데이터베이스에 추가되기 전에 준수해야 하는 미리 정의된 스키마가 없음을 의미합니다. 따라서 데이터 구조를 알 필요가 없으므로 모든 데이터를 쉽고 빠르게 저장할 수 있습니다.
스키마 없는 데이터베이스는 데이터가 관계형 테이블에 저장되지 않기 때문에 NoSQL 데이터베이스라고 합니다. 대신 키-값 쌍, 문서, 열 또는 그래프 데이터 모델과 같은 데이터를 다르게 저장합니다.
3. 문서 지향
몽고DB는 문서 중심 데이터베이스로, 그 자체로 훌륭한 기능입니다. 관계형 데이터베이스에는 데이터를 배열할 수 있는 테이블과 행이 있습니다. 모든 행에는 특정 숫자의 열이 있으며 특정 유형의 데이터를 저장할 수 있습니다.
테이블과 행 대신 필드가 있는 NoSQL의 유연성이 향상되었습니다. 다양한 유형의 데이터를 저장할 수 있는 다양한 문서가 있습니다. 각 문서에는 고유한 키 ID 또는 개체 ID가 있으며, 이 ID는 사용자 또는 시스템으로 정의할 수 있습니다

4. 인덱싱
인덱싱은 검색 쿼리의 성능을 향상시키는 데 매우 중요합니다. 문서에서 지속적으로 검색을 수행할 때는 검색 기준과 일치하는 필드를 색인화해야 합니다.
MongoDB에서는 기본 및 보조 인덱스로 인덱싱된 모든 필드를 인덱싱할 수 있습니다. 쿼리 검색을 더 빠르게 만드는 MongoDB 인덱싱은 성능을 향상시킵니다.

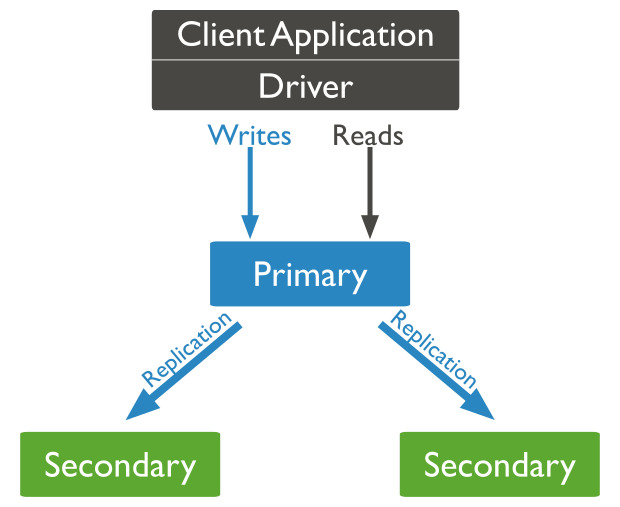
5. 복제
중복성과 관련하여 복제는 MongoDB가 사용하는 도구입니다. 이 기능은 여러 컴퓨터에 데이터를 배포합니다. 주 노드와 하나 이상의 복제본 세트가 있을 수 있습니다. 기본적으로 복제는 만일의 사태에 대비할 수 있게 해줍니다.
어떤 이유로 기본 노드가 다운되면 보조 노드가 인스턴스의 기본 노드가 됩니다. 이를 통해 유지 보수 시간을 절약하고 운영을 원활하게 할 수 있습니다.
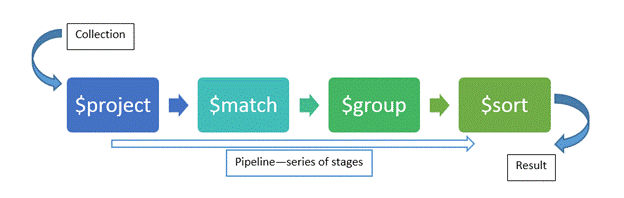
6. 집계
MongoDB에는 효율적인 사용성을 위한 집계 프레임워크가 있습니다. 데이터를 일괄 처리하고 그룹 데이터에 대해 다른 작업을 수행 한 후에도 단일 결과를 얻을 수 있습니다.
집계 파이프라인, map-reduce 기능 및 단일 목적 집계 방법은 집계 프레임워크를 제공하는 세 가지 방법입니다. 우리는 다음 기사에서 그것들을 자세히 볼 것입니다.
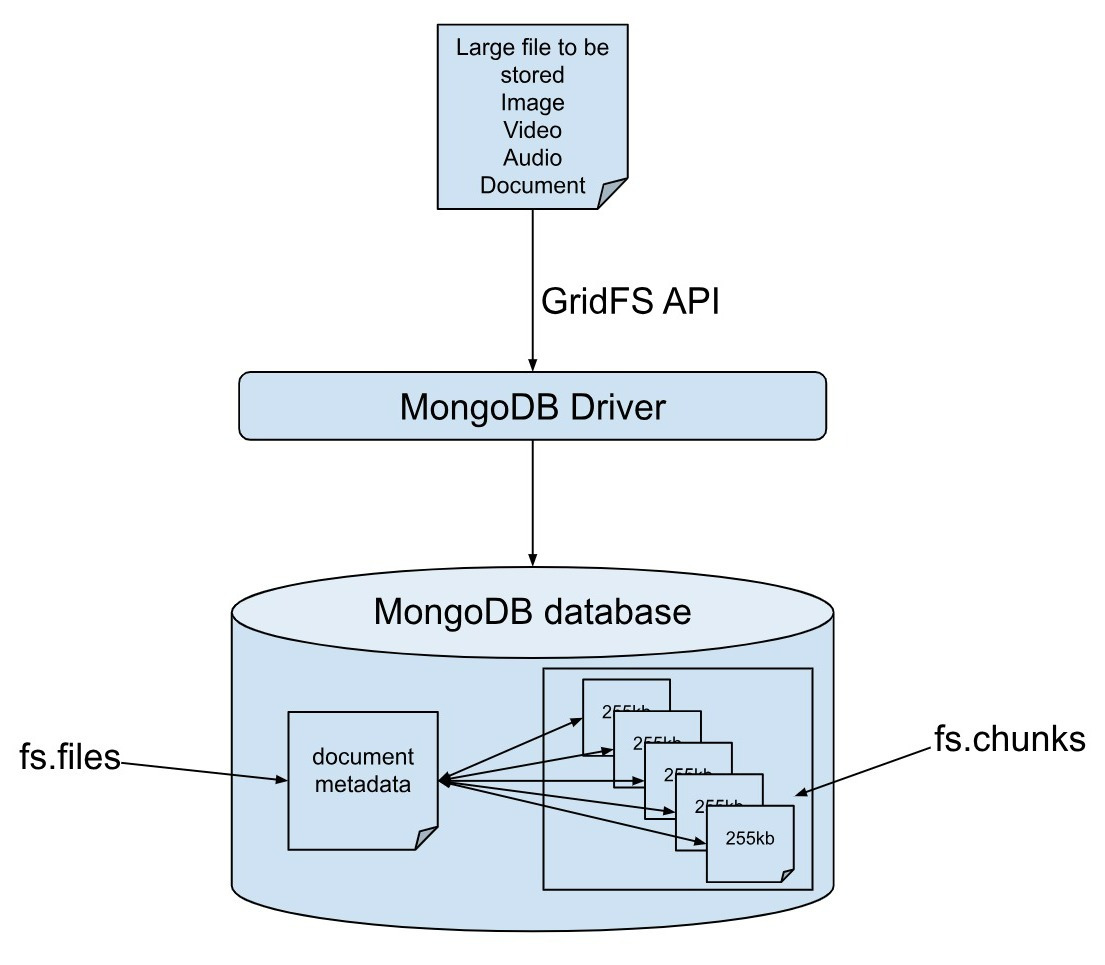
7. GridFS
GridFS는 파일을 저장하고 검색하는 기능입니다. 16MB보다 큰 파일의 경우 이 기능이 매우 유용합니다. GridFS는 문서를 청크라는 부분으로 나누어 별도의 문서에 저장합니다. 이러한 청크의 기본 크기는 마지막 청크를 제외하고 255kB입니다.
GridFS에 파일을 쿼리하면 필요에 따라 모든 청크를 어셈블합니다.
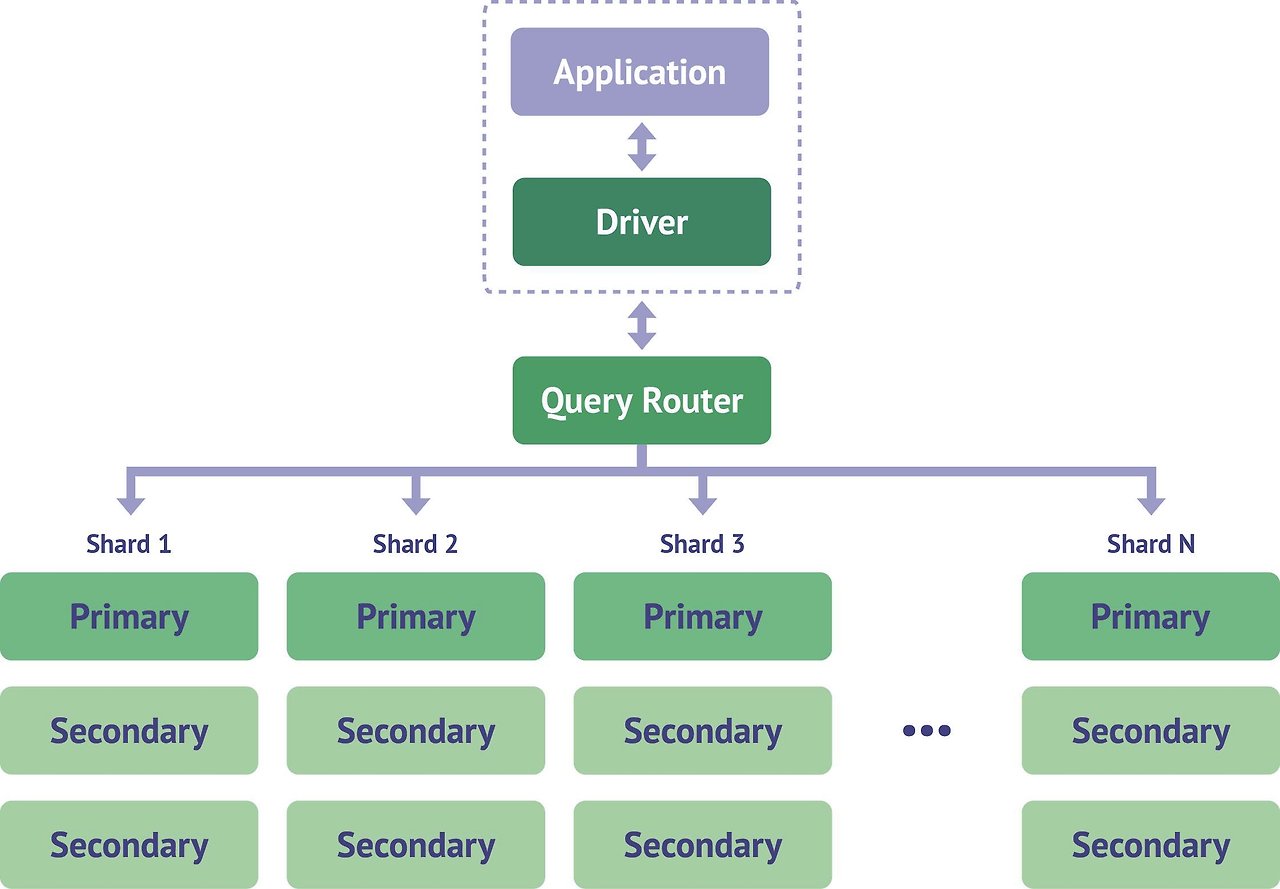
8. 샤딩
기본적으로 샤딩의 개념은 더 큰 데이터 세트를 처리해야 할 때 발생합니다. 이 거대한 데이터는 쿼리가 올 때 몇 가지 문제를 일으킬 수 있습니다. 이 기능은 문제가 있는 데이터를 여러 MongoDB 인스턴스에 배포하는 데 도움이 됩니다.
크기가 더 큰 MongoDB의 컬렉션은 여러 컬렉션으로 배포됩니다. 이러한 컬렉션을 "샤드"라고 합니다. 샤드는 클러스터에 의해 구현됩니다.
9. 고성능
MongoDB는 고성능의 오픈 소스 데이터베이스입니다. 이는 고가용성 및 확장성을 보여줍니다. 인덱싱 및 복제로 인해 쿼리 응답이 더 빠릅니다. 따라서 빅 데이터 및 실시간 응용 프로그램에 더 나은 선택입니다.
'프로그래밍 > AI' 카테고리의 다른 글
| 몽고DB의 데이터 유형 (0) | 2024.10.10 |
|---|---|
| 몽고DB 설치 및 환경설정 방법 (0) | 2024.10.10 |
| 몽고DB의 개요, 기능, 동작방식 소개 (0) | 2024.10.09 |
| 텐서플로의 이해 (TensorFlow) (0) | 2024.10.09 |
| 머신러닝을 사용한 이미지 분할하는 방법 (0) | 2024.10.08 |