문자열 데이터 타입

문자열은 디스플레이할 수 있거나 또는 디스플레이할 수 없는 일련의 ASCII 문자입니다. 문자열의 정보 및 데이터 포맷은 플랫폼에 의존적이지 않습니다. 일반적으로 문자열은 다음과 같은 작업에 사용됩니다:
단순 텍스트 메시지 생성.
인스트루먼트에 텍스트 명령을 보내 인스트루먼트를 통제하고, ASCII 또는 2진 문자열 형식으로 데이터 값을 반환한 후 이를 숫자형 값으로 변환.
숫자형 데이터를 디스크에 저장. ASCII 파일에 숫자형 데이터를 저장하려면, 디스크 파일에 데이터를 쓰기 전에 반드시 숫자형 데이터를 문자열로 변환해야 합니다.
대화 상자를 사용하여 사용자에게 지시 또는 입력요청.
프런트패널에서 문자열은 테이블, 문자 입력 박스 및 라벨로 나타납니다. LabVIEW에는 문자열 포맷, 분석 및 기타 편집과 같은 문자열 작업에 활용할 수 있는 VI와 함수들이 포함되어 있습니다. LabVIEW에서 문자열 데이터는 분홍색으로 표시됩니다.
숫자형 데이터 타입


LabVIEW는 숫자형 데이터를 부동소수, 고정 소수점 수, 정수, 부호없는 정수 및 복소수로 나타냅니다. LabVIEW에서는 복소수 데이터 뿐 아니라 배정도 및 단정도도 주황색으로 표시됩니다. 모든 정수 데이터는 파란색으로 표시됩니다.
숫자형 데이터 타입들 간의 차이는 데이터 저장에 사용하는 비트 수와 나타내는 데이터 값의 차이입니다.
또한 일부 데이터 타입은 확장된 설정 옵션을 제공합니다.
예를 들어, 물리적 측정 단위를 복소수를 포함한 부동소수 데이터와 연계하고, 고정 소수점 데이터에 대한 인코딩과 범위를 설정할 수 있습니다.
불리언 데이터 타입

LabVIEW는 불리언 데이터를 8비트 값으로 저장합니다. LabVIEW에서 0 또는 1, 또는 참/거짓을 표시할 때 불리언을 사용합니다. 8비트 값이 0(zero)인 경우 불리언 값은 거짓(FALSE)입니다.
0이 아닌 모든 값은 참(TRUE)을 나타냅니다. 일반적인 불리언 데이터 어플리케이션에는 디지털 데이터를 표시하고, 케이스 구조와 같은 실행 구조를 컨트롤할 때 사용하는 기계적 동작을 하는 스위치 역할을 하는 프런트패널 컨트롤이 있습니다. 일반적으로 불리언 컨트롤은 While 루프를 종료하기 위한 조건 명령으로 사용됩니다.
LabVIEW에서 불리언 데이터는 녹색으로 표시됩니다.
다이나믹 데이터 타입

대부분의 익스프레스 VI는 짙은 파란색 터미널로 보이는 다이나믹 데이터 타입을 받거나 반환합니다.
[다이나믹 데이터로 변환] 및 [다이나믹 데이터로부터 변환] VI를 사용하면, 다음 데이터 타입의 부동소수 숫자형 또는 불리언 데이터를 변환할 수 있습니다.
웨이브폼의 1D 배열
스칼라의 1D 배열
스칼라의 1D 배열 ― 가장 최근값
스칼라의 1D 배열 ― 단일 채널
스칼라의 2D 배열 ― 열이 채널이 됨
스칼라의 2D 배열 ― 행이 채널이 됨
단일 스칼라
단일 웨이브폼
다이나믹 데이터 타입을 가장 효과적으로 제시할 수 있는 인디케이터에 이를 연결하도록 합니다. 인디케이터에는 그래프, 차트 또는 숫자형 인디케이터가 있습니다.
그러나 다이나믹 데이터는 와이어로 연결된 인디케이터에 맞게 자동으로 변환되므로, 익스프레스 VI는 블록다이어그램의 실행 속도를 지연시킬 수 있습니다.
다이나믹 데이터 타입은 주로 익스프레스 VI와 함께 사용하기 위한 것입니다. LabVIEW와 함께 제공되는 대부분의 다른 VI와 함수는 이 데이터 타입을 받아 들이지 않습니다.
LabVIEW에 있는 VI 또는 함수를 사용해서 다이나믹 데이터를 분석하거나 처리하려면, 반드시 다이나믹 데이터 타입을 다른 데이터 타입으로 변환시켜야 합니다.
배열
서로 연관된 데이터를 하나의 그룹으로 묶는 것이 유용할 때가 있습니다. LabVIEW에서는 배열과 클러스터를 통해 서로 연관성이 있는 데이터를 그룹으로 묶을 수 있습니다. 배열은 동일한 타입의 여러 데이터 포인트를 하나의 데이터 구조로 통합한 것이고, 클러스터는 서로 다른 다양한 타입의 데이터 포인트를 하나의 구조로 통합한 것입니다.
배열은 원소와 차원으로 구성됩니다. 원소는 배열을 구성하는 데이터입니다. 차원은 배열의 길이, 높이 또는 폭을 지칭합니다. 배열은 하나 또는 그 이상의 차원을 가질 수 있으며, 메모리가 허용하는 경우 차원마다 (231)—1개의 원소가 있을 수 있습니다.
숫자형, 불리언, 경로, 문자열, 웨이브폼, 클러스터 데이터 타입으로 배열을 만들 수 있습니다. 비슷한 데이터 포인트를 모아서 작업을 하거나 반복된 연산을 수행하는 경우 배열을 사용하는 것이 좋을 수 있습니다. 웨이브폼에서 수집한 데이터 및 루프에서 생성된 데이터를 저장하는 경우 배열을 사용하면 이상적입니다.
이 경우, 루프는 매 반복마다 배열의 원소를 하나씩 생성하게 됩니다.
LabVIEW의 배열 인덱스는 0에서 시작합니다. 배열에 있는 첫번째 원소의 인덱스는 차원에 관계없이 0입니다.
배열의 원소에는 순서가 있습니다. 배열에서는 인덱스를 사용하여, 사용자가 특정 원소에 접근할 수 있도록 합니다. 인덱스는 0부터 시작되며, 이는 곧 n개의 원소가 있는 배열의 경우 인덱스의 범위는 0에서 n-1이 됨을 의미합니다. 예를 들어, n-12가 1년의 12달을 나타내는 경우 인덱스는 0에서 11이 됩니다. 3월은 세번째 달이므로 3월에 대한 인덱스는 2가 됩니다.
그림 1은 숫자형의 배열의 예를 보여줍니다. 이 배열에서 보이는 첫번째 원소(3.00)는 인덱스 1에 있으며, 두번째 원소(1.00)는 인덱스 2에 있습니다. 인덱스 디스플레이에서 원소 1이 선택되었기 때문에, 이 그림에서 인덱스 0의 원소는 보이지 않습니다. 인덱스 디스플레이에서 선택된 원소는 항상 원소 디스플레이의 가장 왼쪽 위에 위치하게 됩니다.
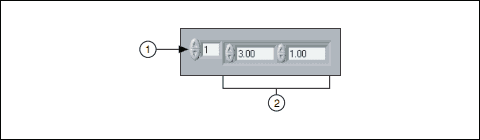
(1) 인덱스 디스플레이 | (2) 원소 디스플레이
그림 1. 숫자형의 배열 컨트롤
배열 컨트롤과 인디케이터 생성하기
그림 2와 같이 프런트패널에 배열 쉘을 추가한 후, 숫자형이나 문자열 등의 데이터 객체 및 원소를 배열 쉘 안에 끌어 놓아서 프런트패널에 배열 컨트롤이나 배열 인디케이터를 만들 수 있습니다.
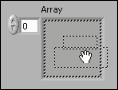
그림 2. 배열 쉘에 숫자형 컨트롤 놓기
배열 쉘 안에 적합하지 않은 컨트롤 및 인디케이터를 끌어 오는 경우 해당 컨트롤이나 인디케이터를 배열 쉘에 놓을 수 없게 됩니다.
배열 쉘에 먼저 객체를 삽입해야 블록다이어그램에서 배열을 사용할 수 있습니다. 그렇지 않은 경우, 블록다이어그램 상에서 배열은 안에 빈 사각 대괄호가 있는 검정색 터미널로 표시되며, 데이터 타입이 설정되지 않습니다.
2차원 배열
이전 예제에서는 1D 배열을 사용했습니다. 2D 배열에서는 원소를 눈금으로 저장합니다. 특정 원소를 찾으려면 행 인덱스와 열 인덱스가 필요하며, 이 인덱스들은 0을 기준으로 시작합니다. 그림 3은 8×8 = 64 원소가 있는 2D 배열의 8행과 8열을 보여줍니다.

그림 3. 2D 배열
프런트패널에 다차원 배열을 추가하려면, 인덱스 디스플레이에서 마우스 오른쪽 버튼을 클릭한 후 바로 가기 메뉴에서 차원 추가를 선택합니다. 또한 인덱스 디스플레이의 크기를 조정하여 원하는 수만큼의 차원을 만들 수 있습니다.
배열 초기화하기
배열을 초기화하거나 초기화하지 않은 채로 둘 수 있음. 배열을 초기화하면, 각 차원에 있는 원소의 개수 및 각 배열의 내용을 정의할 수 있습니다. 초기화되지 않은 배열에는 지정한 수의 차원이 있지만, 안에 원소가 포함되어 있지는 않습니다. 그림 4는 초기화되지 않은 2D 배열 컨트롤을 보여줍니다. 이 배열 안에 있는 모든 원소는 모두 흐릿하게 보입니다. 이는 이 배열이 초기화되지 않았음을 나타냅니다.
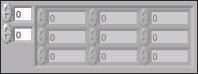
그림 4. 초기화되지 않은 2D 배열
2D 배열에서 하나의 원소를 초기화하면, 그 열과 이전 열에 있는 초기화되지 않은 원소들이 해당 데이터 타입의 기본값으로 초기화되어 채워집니다. 그림 5에서는 0부터 시작하는 배열의 2열에 4라는 값이 입력되었습니다. 0, 1, 2열에 있는 이전 원소는 숫자형 데이터 타입의 기본값인 0으로 초기화됩니다.
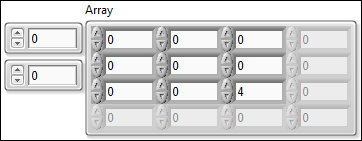
그림 5. 9개의 원소를 가진 초기화된 2D 배열
배열 상수 생성하기
블록다이어그램에서 배열 상수를 생성하려면, 함수 팔레트에서 배열 상수를 선택하고 블록다이어그램에 배열 쉘을 놓은 후, 문자열 상수, 숫자형 상수, 불리언 상수 또는 클러스터 상수를 배열 쉘 안에 놓습니다. 배열 상수는 상수 데이터를 저장하거나, 다른 배열과 비교를 하기 위한 기준으로 사용할 수 있습니다.
배열 입력 오토인덱싱하기

For 루프 또는 While 루프에 배열을 연결하는 경우, 오토인덱싱을 활성화하여 루프의 각 반복을 배열의 원소에 연계시킬 수 있습니다. 이때 속이 채워진 사각형 모양의 터널은 다음 그림처럼 바뀌어 오토인덱싱이 활성화되었음을 나타냅니다.
터널에서 마우스 오른쪽 버튼을 클릭하고 바로 가기 메뉴에서 인덱싱 활성화 또는 인덱싱 비활성화를 선택하여 터널의 상태를 변경할 수 있습니다.
배열 입력
For 루프의 입력 터미널에 연결된 배열에 오토인덱싱을 활성화하면, 사용자가 카운트 터미널에 연결할 필요없이 LabVIEW가 카운트 터미널을 배열 크기에 맞추어 자동 설정합니다. For 루프를 사용하면 한 번에 한 원소씩 배열을 처리할 수 있으므로, LabVIEW에서는 배열을 For 루프에 연결하면 오토인덱싱 활성화 상태가 되도록 기본 설정되어 있습니다.
배열에서 반드시 한 번에 하나씩 원소를 처리할 필요가 없는 경우에는 오토인덱싱을 비활성화 상태로 설정할 수 있습니다.
그림 6에서 보이는 For 루프는 배열 안의 원소 개수와 동일한 횟수만큼 실행이 반복됩니다. 보통 For 루프에 카운트 터미널이 연결되지 않으면 VI의 실행 화살표는 깨집니다. 하지만 그림에 보이는 For 루프의 경우에는 실행 화살표가 깨지지 않습니다.
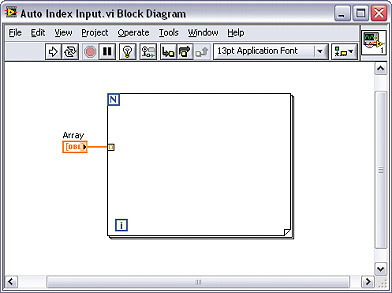
그림 6. For 루프의 카운트를 설정하는 배열
하나 이상의 터널에 오토인덱싱을 활성화하거나 카운트 터미널을 연결하면 더 작은 카운트가 실제 반복 횟수로 선택됩니다. 예를 들어, 각각 10 개와 20 개의 원소가 있는 오토인덱싱된 2개의 배열을 루프에 입력하고 카운트 터미널에 값 15를 연결하는 경우, 이 루프는 10 회만 실행되고 두 배열의 처음 10개의 원소가 인덱싱됩니다.
배열 출력
배열 출력 터널을 오토인덱싱하면, 해당 출력 배열은 루프가 반복될 때마다 새로 생성되는 원소를 받습니다. 그러므로 오토인덱싱된 출력 배열의 크기는 항상 반복 횟수와 같습니다.
출력 터널과 배열 인디케이터를 연결하는 와이어는 루프 경계에서 배열로 바뀌면서 굵어지고, 출력 터널 안에는 배열을 나타내는 사각 대괄호가 나타납니다.
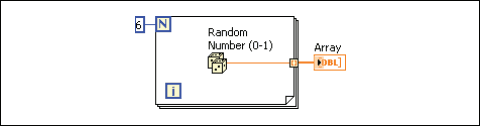
그림 7. 오토인덱싱된 출력
루프 경계의 터널에서 마우스 오른쪽 버튼을 클릭한 후 바로 가기 메뉴에서 인덱싱 활성화 또는 인덱싱 비활성화를 선택하여 오토인덱싱을 활성화하거나 비활성화할 수 있습니다. While 루프에서는 오토인덱싱이 비활성화되도록 기본 설정되어 있습니다.
2차원 배열 생성하기
하나의 루프 안에 다른 루프가 들어있는 형식으로, 2 개의 For 루프를 사용하여 2D 배열을 생성할 수 있습니다. 바깥쪽 For 루프는 행의 원소를 생성하며, 안쪽 For 루프는 열의 원소를 생성합니다.
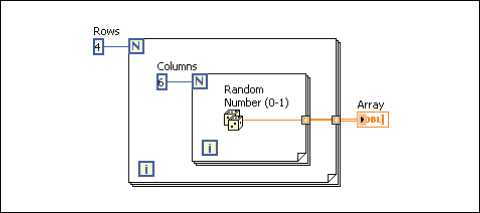
그림 8. 2D 배열 생성하기
클러스터
클러스터는 여러가지 타입의 데이터 원소를 하나의 그룹으로 묶음. 불리언, 숫자형, 문자열 값을 통합한 LabVIEW의 에러 클러스터는 대표적인 클러스터의 예 중 하나입니다. 클러스터는 텍스트 기반 프로그래밍 언어에서의 레코드(record) 또는 구조체(struct)와 유사합니다.
여러 데이터 원소를 클러스터로 묶으면, 블록다이어그램에서 와이어의 복잡한 연결을 피할 수 있으며 SubVI에 필요한 커넥터 팬 터미널의 수를 줄일 수 있습니다. 커넥터 팬은 최대 28개의 터미널을 가질 수 있습니다. 프런트패널에 다른 VI로 전달하려는 컨트롤 및 인디케이터가 28개 이상 있는 경우, 이 중 일부를 클러스터로 그룹화하고 이 클러스터를 커넥터 팬의 터미널 하나에 할당하면 됩니다.
블록다이어그램에서 대부분의 클러스터는 분홍색의 와이어 패턴과 데이터 타입 터미널을 갖습니다. 에러 클러스터의 와이어 및 데이터 타입 터미널은 짙은 노란색입니다. 때때로 포인트를 나타내기도 하는 숫자형 값의 클러스터는 갈색의 와이어 패턴 및 데이터 타입 터미널을 갖습니다.
갈색 숫자형 클러스터를 [더하기]나 [제곱근]과 같은 숫자형 함수에 연결하면, 클러스터의 모든 원소에 동일한 연산 작업을 동시에 수행할 수 있습니다.
클러스터 원소의 순서
클러스터와 배열 원소는 모두 순서대로 배열되어 있지만, 클러스터 원소를 풀 때에는 [풀기] 함수를 사용하여 모든 원소를 한꺼번에 풀어야 합니다. [이름으로 풀기] 함수를 사용하여 이름을 기준으로 클러스터 원소를 풀 수 있습니다. [이름으로 풀기] 함수를 사용하는 경우, 각 클러스터 원소에 라벨이 있어야 합니다. 또한, 클러스터는 고정된 크기를 갖는다는 점에서 배열과 다릅니다. 배열과 마찬가지로 클러스터는 컨트롤이거나 인디케이터 둘 중 하나가 될 수 있습니다. 클러스터 안에는 컨트롤과 인디케이터가 함께 포함될 수 없습니다.
클러스터 컨트롤과 인디케이터 생성하기
다음 프런트패널에서 보이는 것처럼 프런트패널에 클러스터 쉘을 추가한 후 숫자형, 불리언, 문자열, 경로, 참조 번호, 배열, 클러스터 컨트롤 또는 인디케이터 등의 데이터 객체 또는 원소를 클러스터 쉘에 끌어다 놓아서 프런트패널에 클러스터 컨트롤 또는 인디케이터를 생성합니다.
클러스터 쉘을 놓을 때 커서를 끌어서 클러스터 쉘의 크기를 조정할 수 있습니다.
그림 9. 클러스터 컨트롤 생성하기
그림 10은 문자열, 불리언 스위치, 숫자형의 세 가지 컨트롤이 들어 있는 클러스터의 예입니다.
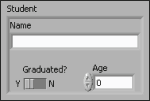
그림 10. 클러스터 컨트롤의 예
클러스터 상수 생성하기
블록다이어그램에서 클러스터 상수를 생성하려면, 함수 팔레트에서 클러스터 상수를 선택하고 블록다이어그램에 클러스터 쉘을 놓은 후, 문자열 상수, 숫자형 상수, 불리언 상수 또는 클러스터 상수를 클러스터 쉘 안에 놓습니다. 클러스터 상수는 다른 클러스터와 비교를 하기 위한 기준으로 사용하거나, 상수 데이터를 저장하는데 활용할 수 있습니다.
프런트패널 윈도우에 클러스터 컨트롤이나 인디케이터가 있는 상태에서 이와 동일한 원소를 포함하는 클러스터 상수를 블록다이어그램에 생성할 수 있습니다. 이 경우에는 프런트패널 윈도우에서 블록다이어그램으로 클러스터를 끌어오거나, 블록다이어그램의 클러스터에서 마우스 오른쪽 버튼을 클릭하고 바로 가기 메뉴에서 생성≫상수를 선택하면 됩니다.
클러스터 함수 사용하기
클러스터 함수를 사용하여 클러스터를 생성하고 조작할 수 있습니다. 클러스터 함수를 통해 수행할 수 있는 작업에는 다음과 같은 예들이 있습니다:
클러스터에서 특정 데이터 원소를 개별적으로 추출하기
클러스터에 특정 데이터 원소를 개별적으로 추가하기
클러스터를 개별 데이터 원소들로 나누기
[묶기] 함수를 사용하여 클러스터를 병합하고, [묶기]와 [이름으로 묶기] 함수를 사용하여 클러스터를 변경하고, [풀기]와 [이름으로 풀기] 함수를 사용하여 클러스터를 해체할 수 있습니다.
또한 블록다이어그램의 클러스터 터미널에서 마우스 오른쪽 버튼을 클릭하고 바로 가기 메뉴에서 클러스터, 클래스 & 배리언트 팔레트를 선택하여, [묶기], [이름으로 묶기], [풀기], [이름으로 풀기] 함수를 놓을 수 있습니다.
[묶기]와 [풀기] 함수는 자동으로 적절한 수의 터미널을 포함합니다. [이름으로 묶기]와 [이름으로 풀기] 함수는 클러스터 안의 첫번째 원소를 표시하게 됩니다. 위치 도구로 [이름으로 묶기]와 [이름으로 풀기] 함수의 크기를 조정하여, 클러스터의 다른 원소를 표시할 수 있습니다.
클러스터 병합하기
[묶기] 함수를 사용하여 개별 원소로부터 클러스터를 만들거나, 모든 원소에 새 값을 지정하지 않고도 기존 클러스터 안에 있는 특정 원소 값을 변경할 수 있습니다. 함수의 크기를 조정할 때에는 위치 도구를 사용하거나, 원소의 입력에서 마우스 오른쪽 버튼을 클릭한 후 바로 가기 메뉴에서 입력 추가를 선택합니다.
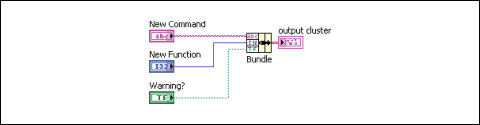
그림 11. 블록다이어그램에서 클러스터 병합하기
클러스터 변경하기
클러스터 입력을 연결할 때에는 변경하고자 하는 원소만 연결할 수 있습니다. 예를 들어 그림 12의 입력 클러스터에는 세 가지 컨트롤이 있습니다.
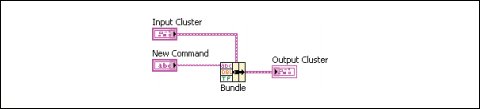
그림 12. [묶기] 함수를 통해 클러스터 변경하기
클러스터의 순서를 아는 경우 그림 12와 같이 원소를 연결하여 [묶기] 함수를 통해 명령 값을 변경할 수 있습니다.
또한 [이름으로 묶기] 함수를 사용하여 라벨이 있는 기존 클러스터의 원소를 대체하거나 사용할 수 있습니다. [이름으로 묶기] 함수는 [묶기] 함수와 기능이 유사하지만, 클러스터 순서가 아닌 원소의 고유 라벨을 기준으로 클러스터 원소를 참조한다는 점이 다릅니다. 고유 라벨을 가진 원소에만 접근할 수 있습니다.
입력의 개수는 출력 클러스터의 원소 개수와 반드시 일치할 필요는 없습니다.
수행 도구를 사용하여 입력 터미널을 클릭하고 풀다운 메뉴에서 원소를 선택합니다. 또한 입력에서 마우스 오른쪽 버튼을 클릭하고 아이템 선택 바로 가기 메뉴에서 원소를 선택하는 방법도 있습니다.
그림 13에서 [이름으로 묶기] 함수를 사용하여 명령과 함수의 값을 새 명령과 새 함수의 값으로 업데이트합니다.
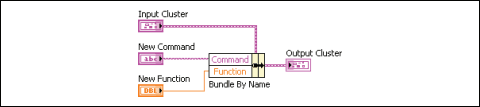
그림 13.[이름으로 묶기] 함수를 통해 클러스터 변경하기
도중에 변경될 가능성이 있는 데이터 구조에는 [이름으로 묶기]를 사용합니다. 새 원소를 클러스터에 추가하거나 순서를 변경하는 경우에도 원소의 고유 이름은 계속 유효하기 때문에 [이름으로 묶기] 함수를 다시 연결할 필요가 없습니다.
클러스터 해체하기
[풀기] 함수를 사용하여 클러스터를 개별 원소로 풀어놓을 수 있습니다.
[이름으로 풀기] 함수를 통해 사용자가 지정한 이름의 클러스터의 원소를 가져올 수 있습니다. 출력 터미널의 개수가 입력 클러스터의 원소 개수에 의해 결정되는 것은 아닙니다.
수행 도구를 사용하여 출력 터미널을 클릭하고 풀다운 메뉴에서 원소를 선택합니다. 또한 출력 터미널에서 마우스 오른쪽 버튼을 클릭하고 아이템 선택 바로 가기 메뉴에서 원소를 선택하는 방법도 있습니다.
예를 들어, 그림 14에서 보이는 것처럼 [풀기] 함수를 클러스터와 함께 사용하는 경우, 클러스터의 네 개의 컨트롤에 해당하는 네 개의 출력 터미널이 생성됩니다. [풀기] 함수를 통해 해제된 클러스터의 불리언 터미널을 이와 대응되는 올바른 클러스터의 스위치와 연계시키려면, 반드시 클러스터 순서를 알아야 합니다.
이 예에서의 원소는 원소 0부터 시작하여 위에서 아래로 순서가 정해져 있습니다. [이름으로 풀기] 함수를 사용하면 적절한 출력 터미널 개수를 갖게 되고, 순서와 상관없이 이름을 사용하여 개별 원소에 접근할 수 있습니다.
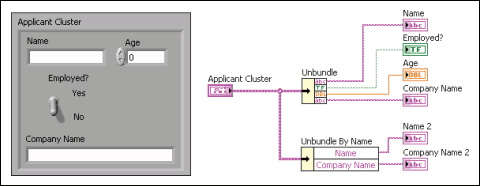
그림 14. [풀기]와 [이름으로 풀기]
열거형
열거형(열거형 컨트롤, 상수 또는 인디케이터)은 데이터 타입의 조합입니다. 열거형은 하나의 문자열과 하나의 숫자형으로 이루어진 한 쌍의 값을 지칭합니다. 열거형 데이터는 여러 값으로 이루어진 리스트에 있는 하나의 값이 될 수 있습니다.
예를 들어, 월(Month)이라는 열거형 데이터 타입을 생성한 경우, 월의 변수가 될 수 있는 값으로는 1월-0, 2월-1, ..., 12월-11 등의 쌍이 있습니다. 그림 15는 열거형 컨트롤의 프로퍼티 대화 상자에 있는 데이터 쌍의 예를 보여줍니다. 열거형 컨트롤에서 마우스 오른쪽 버튼을 클릭하고 아이템 편집을 선택하여 직접 접근할 수 있습니다.
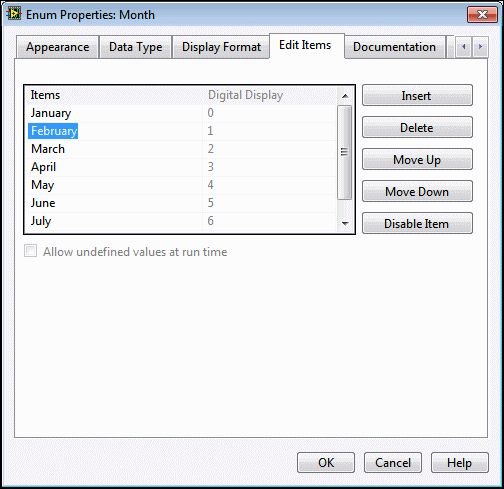
그림 15. 월 열거형 컨트롤의 프로퍼티
블록다이어그램에서는 문자열보다 숫자를 다루는 것이 더 쉽기 때문에, 열거형은 매우 유용하게 사용됩니다. 그림 16은 월의 열거형 컨트롤, 열거형 컨트롤에 있는 데이터 쌍의 선택, 열거형 컨트롤의 블록다이어그램 터미널을 보여줍니다.
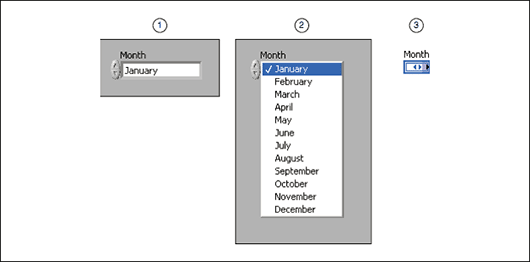
(1) 프런트패널 컨트롤 | (2) 아이템 선택하기 | (3) 블록다이어그램 터미널
그림 16. 월 열거형 컨트롤
프로브 도구

프로브 도구를 사용하면 실행 중인 VI에서 와이어의 중간값을 확인할 수 있습니다.
여러 개의 연속적인 작업으로 구성된 복잡한 블록다이어그램의 경우, 어느 동작에서 잘못된 데이터가 반환되는지 알아보기 위해 프로브 도구를 사용합니다. 프로브 도구를 실행 하이라이트, 단계별 실행, 브레이크포인트와 함께 사용하면, 잘못된 데이터의 유무 여부와 그 위치를 확인할 수 있습니다. 잘못된 데이터가 있는 경우, 프로브는 즉시 업데이트를 하고 해당 데이터를 실행 하이라이트,단계별 실행, 또는 브레이크포인트에서 일시정지할 때 프로브 관찰 윈도우에 디스플레이합니다. 또한 단계별 실행 또는 브레이크포인트로 인해 노드에서 일시 정지 상태일 때, 방금 실행된 와이어를 프로브하면 해당 와이어를 따라 진행 중인 값을 볼 수 있습니다.
'프로그래밍 > 랩뷰 기술자료' 카테고리의 다른 글
| 랩뷰 엑셀보고서 만들기 (0) | 2023.06.08 |
|---|---|
| 랩뷰 공유 라이브러리(Dll-Dynamic Link Library) 호출하기 (0) | 2023.06.08 |
| 랩뷰의 배열 및 클러스터 (0) | 2023.06.04 |
| 랩뷰 시프트 레지스터 (Shift Register) (0) | 2023.06.04 |
| 랩뷰의 실행구조 (0) | 2023.06.04 |